

We do not speak like this
 One of the big differences between native speakers of English and non-natives is that non-natives
One of the big differences between native speakers of English and non-natives is that non-natives do not don’t use contractions nearly as much.
This is related to the tendency for foreign languages to be taught in their written form. Contractions are not aren’t used in formal writing, for instance in academic journals. They can be seen here and there in newspapers: I have I’ve just glanced at a copy of the Guardian and found “there’s also Osborne the pragmatist” and “you don’t have to look far to see which banks will pay more”. But contractions are relatively rare in print.
By contrast, they are they’re a basic part of spoken English. I adopt a fairly conversational style in my website, and that is that’s why you will you’ll find quite a lot of contractions here.
Let us Let’s listen to some spoken examples from popular Brits. Stephen Fry:
I’m always getting myself into trouble… That’s the point of democracy… We don’t have enough of it.
Dame Judi Dench:
It’s pretty cool… Why can’t I find a play… If they don’t make a difference, I’ll be home here.
Benedict Cumberbatch:
A profession that’s very challenging… You’re asked to use your imagination… Meeting that challenge in a way that’ll hopefully make my peers, my family and my friends proud.
Contractions are not aren’t always used in speech. Sometimes, eg for emphasis, they are not used. But it sounds extremely formal or stilted to avoid them completely. The Queen might say It is no accident that they are known as the friendly games:
but in more normal speech this would be It’s no accident that they’re known as the friendly games.
The main categories of contractions
1. Modal/auxiliary verb + not: don’t, can’t, won’t, aren’t, weren’t, couldn’t, mustn’t, etc
2. Especially after pronouns:
• the verb be in the present: I’m, you’re, she’s, etc
• auxiliary have in both present and past: I’ve, I’d, you’ve, you’d, she’s, she’d, etc
• will/shall: I’ll, you’ll, she’ll, etc
• would: I’d, you’d, she’d, etc3. let’s

Collect your colleagues
 A word which non-natives often pronounce differently from native speakers is colleague. The native pronunciation is stressed on the first syllable, cólleague:
A word which non-natives often pronounce differently from native speakers is colleague. The native pronunciation is stressed on the first syllable, cólleague:
Non-native learners and users of English, even very proficient ones, often put the stress on the last syllable, colléague:
The simple way to get the native pattern right is to remember that colleague isn’t a verb. (A verb is a ‘doing word’.) All of the 2-syllable coll- words with final stress are verbs. Here they are, in descending order of frequency on the web:
collect, collapse, collate, collide, collude
Each of those verbs begins with a weak syllable containing the little colourless vowel ‘schwa’, ə. The most common by far are collect and collapse: in Oxford Dictionaries transcription, /kəˈlɛkt/ and /kəˈlaps/.
2-syllable coll- words with initial stress are generally nouns (‘naming words’), and colleague conforms to this pattern. The most common are:
college, Collins, colleague, collar
(The last of these can be used informally as a verb, meaning ‘to stop someone, as if grabbing them by their collar’ – for example, he was collared by the police. In this usage collar keeps its initial stress.)
So a handy phrase for remembering this might be Colléct your cólleagues.

Djokovic, the jokey jock
 Novak Djokovic, Serbia’s world no. 1 tennis player, has won the Wimbledon Gentlemen’s Singles for the third time.
Novak Djokovic, Serbia’s world no. 1 tennis player, has won the Wimbledon Gentlemen’s Singles for the third time.
Djokovic has different pronunciations in England and the US. In England, the beginning is pronounced like jock, while in the US it’s pronounced like joke. Here are two BBC commentators. First, Englishman Tim Henman:
Second, American Andy Roddick:
The American pronunciation conforms to a pattern I described in an article 25 years ago: in the stressed syllables of foreign loanwords, American English likes to use five ‘tense’ vowels for the five vowel letters of the alphabet: PALM for a, FACE for e, FLEECE for i, GOAT for o, GOOSE for u. This is why Americans use the vowel of GOAT (and of joke) in eg Kosovo, Nokia, Prokofiev, Sochi and Djokovic.
The English, on the other hand, have an extra vowel which Americans don’t have: their ‘short-lax’ LOT vowel. It’s the vowel that sounds so English in Harry Potter. Americans use the PALM vowel in such words, pronouncing the first syllable of Potter like the last syllable of grandpa. The English also use their LOT vowel in jock (which Americans rhyme with Bach).
This LOT vowel is also quite near to the Serbian o, which we can hear from native speakers of Serbian on the valuable Forvo site:
So, if we were evaluating the competing pronunciations of Djokovic in England and the US, we might conclude that it’s 15-love to England.
But it’s not quite that simple. Both the Americans and the English use the GOAT vowel in Novak. That is, Americans use the same vowel in Novak and Djokovic, while the English use different vowels. Serbian has the same vowel quality in the two names, so the English are being inconsistent in using different qualities. The English also get the vowel lengths the wrong way round, with long GOAT in Novak and short LOT in Djokovic: the Serbian o is short in Novak and long in Djokovic. (This can be heard particularly from the two male native speakers.)
Deuce?
Brits and Americans often find each other’s pronunciations of foreign words strange, even ‘wrong’. But the pronunciation of loanwords results from a combination of factors, including spelling pronunciation conventions and, crucially, the sound system of the borrowing dialect. It’s generally not a simple matter of linguistic expertise.
(Jock is an informal American word for an athlete, and Novak Djokovic is known for his jokey impressions of other players.)
Further notes
My 1990 article discussed various possible reasons for the emergence of the American 5-vowel loanword strategy. One is the influence of Spanish, the best-known and most-used foreign language in the US. Another is the loss from the speech of many (perhaps most) Americans of a distinct THOUGHT vowel; for these speakers PALM, FACE, FLEECE, GOAT, GOOSE are arguably a distinct natural class within the AmE vowel system.
There are plenty of exceptions to the strategy. One is Federer (a long vowel in German), which ‘should’ get the tense FACE vowel, as in Mercedes, but which Americans typically say with the lax DRESS vowel. The similarity to the English word federal may be the reason.
If loanword pronunciations were driven only by phonetic considerations, then the SSB THOUGHT vowel would be a fair candidate for Djokovic. But it violates spelling conventions: a simple o in spelling is never pronounced with the THOUGHT vowel. As I discussed in a blog post here, this explains why the phonetically-appropriate THOUGHT vowel was a non-starter for English correspondents pronouncing Sochi. As with Djokovic, SSB speakers used their LOT vowel and Americans used their GOAT vowel in Sochi.
An amusing but hard-to-hear YouTube video shows Novak Djokovic giving advice on the pronunciation of his name to American tennis-champion-turned-commentator Jim Courier. The two men are at cross purposes: Courier, if I hear right, wants to know whether he should use his GOAT or his PALM vowel in the first syllable, while Djokovic wants to talk about the initial consonant [dʑ], written Đ or Ђ in Serbian – another non-starter for English speakers.
Warning: count(): Parameter must be an array or an object that implements Countable in /afs/intranet.ailesse.eu/service/www/com/englishspeechservices/www/web/wp-content/plugins/yop-poll/models/poll_model.php on line 1060

Harry Potter and the Cursed Child
J. K. Rowling has announced an upcoming stage play Harry Potter and the Cursed Child. As I explain in the video, the word cursed can be pronounced as one or two syllables. The two-syllable version is rather old-fashioned and means either ‘bearing a curse’ or ‘deserving to be cursed, annoying’. On the other hand, the one-syllable form of cursed ends in a t sound which my be omitted when followed by a word like child, making cursed child sound like curse child. (Think of firs’ class and wors’ case scenario.)
Further notes
More precisely, t and d may be dropped from the end of a word when the next word begins with a consonant and the t or d is preceded by a consonant with the same degree of voicing. The way to remember this is with the pair firs’ class, secon’ class. The t may be lost from first because both it and the preceding s are voiceless (or ‘fortis’). The d may be lost from second because both it and the preceding n are voiced (or ‘lenis’).
The stressed vowel of cursed is the NURSE vowel, a long schwa, which is also the English hesitation vowel. The unstressed vowel may be either schwa or the KIT vowel ɪ.

My lawful wedded wife
 On Friday I attended a register office wedding. At civil marriages in England and Wales, the spoken vows must include words of this type: ‘I [name] do take thee [name] to be my lawful wedded wife/husband’.
On Friday I attended a register office wedding. At civil marriages in England and Wales, the spoken vows must include words of this type: ‘I [name] do take thee [name] to be my lawful wedded wife/husband’.
The wording may be specified, but the intonation isn’t. One of the norms of English intonation is to put the last accent of a phrase on its final noun/verb/adjective/adverb. So, in the wedding vow, we normally get ‘…my lawful wedded wife‘:
But on this occasion the speaker said (with a smile) ‘my lawful wedded wife’, rather like:
which got a good-natured laugh from the many friends and family who were present.
English speakers often break the accentuation norm, in order to show which words refer to already-known things and which words introduce brand new information. They de-accent the final part of a phrase to show that it’s already known, and highlight an earlier word to show that it’s new information. So the pronunciation ‘my lawful wedded wife’ tells us that the person in question was already a wedded wife, and it was only the lawfulness that was new. Hence the laughter.
Not long ago such an implication would have been rather scandalous. But then, so would the fact that it was a same-sex marriage.
Best wishes to the happy couple.
Further notes
The other use of this kind of accent pattern is to point out a contrast. The second pattern above might be used to contrast a lawful wedded wife with one or more non-lawful wedded wives. No polygamy is involved in the present case.

Worse advertising
 Someone I was teaching recently described an upcoming pronunciation course with the phrase worse advertising (= ‘lower quality advertising’). I was taken aback for a moment, until I realized that his intended words were worth advertising (= ‘good enough to be advertised’).
Someone I was teaching recently described an upcoming pronunciation course with the phrase worse advertising (= ‘lower quality advertising’). I was taken aback for a moment, until I realized that his intended words were worth advertising (= ‘good enough to be advertised’).
The problem was that the final sound on his worth was, to my native ears, too much like s. This speaker’s mother tongue doesn’t have a contrast between s and th. Most languages don’t.
English s and th, as in sink and think, worse and worth, are very different sounds. The difference between them is fundamentally acoustic. English s is loud, with a piercing, high timbre, which can cut through background noise such as chatter at a social gathering. English th is much quieter, more like faint ‘white noise’, and therefore would be quite useless for getting someone’s attention at a gathering.
To perceive and produce these sounds accurately, the learner must listen to them and copy them carefully. Here is worth, first with a very quiet th, then a slightly louder one:
And here is worse, with the strong final s that is so characteristic of English:
The difference between the sounds in terms of how they’re made in the mouth is rather complicated. The articulation of English s involves fine muscular adjustments in the tongue which channel a jet of air against the back of the teeth. (This is why those who lose their teeth can’t make a good s sound.) The articulation of English th is less fine-tuned, with a flatter tongue.
Traditional phonetic descriptions of these sounds tend to rely on mid-sagittal cross-sectional diagrams of the mouth, emphasizing ‘place of articulation’ and the idea that s is ‘alveolar’ while th is ‘dental’. In fact s can be dental, and th can be made behind the teeth, or for that matter with the tongue tip at the lips. What matters most, of course, is the difference in sound.
Further notes
English th actually corresponds to two phonetic forms, symbolized θ and ð in the International Phonetic Alphabet (the final sound of worth is θ). These ‘dental fricatives’ are found in less than a tenth of the world’s languages, as John Wells discussed in his blog.
Very many younger speakers in Britain are using f instead of θ, so that three sounds the same as free. Both f and θ are relatively quiet sounds, so this change is not too surprising. It’s considerably more disturbing for native listeners when non-natives use s instead of θ. I discuss these matters with lots of video clips in the blog post here.

Pronunciations that I recommend
 An English word which non-natives often pronounce differently from natives is recommend. Non-natives often pronounce the beginning of the word as if it were like reported or reaction. But natives pronounce this word as if it began with wreck. In other words, the first vowel is the ‘open e’ sound [ɛ] which is found in red, dress, health, said, etc:
An English word which non-natives often pronounce differently from natives is recommend. Non-natives often pronounce the beginning of the word as if it were like reported or reaction. But natives pronounce this word as if it began with wreck. In other words, the first vowel is the ‘open e’ sound [ɛ] which is found in red, dress, health, said, etc:
The first and last syllables are both stressed, and separated by a little colourless ‘schwa’ vowel ə. The final syllable will get the main intonation accent if the word is said alone as a one-word phrase (as in the above clip, and in the audio clips of dictionaries). This means that the word sounds like wreck ə MEND. (In the transcription of eg the Collins and Merriam-Webster Learner’s dictionaries, it’s /ˌrɛkəˈmɛnd/.)
There’s a handful of familiar re- verbs with the same pattern (ie three syllables, strong-weak-strong; the vowel of wreck in the first syllable; and the potential for a heavy accent on the end). They are: recommend, represent, resurrect, recollect (these also have the wreck vowel in the final syllable too), plus reminisce. To these we might add referee – basically a noun, but also used as a verb, as in ‘Who’s going to referee?’
Here are these six verbs:
Further notes
A much less familiar re- verb that follows the same pattern is reprehend. More common is the adjective derived from it, reprehensible (Collins/MWL: /ˌrɛprɪˈhɛnsəbəl/).
For those who like rules, and are comfortable with traditional dictionary symbols, John Wells wrote a detailed blog post about the prefix re-, here.

Any time? Any town?
 I’m always grateful when readers tell me about typos (typographical errors) in my posts. One reader has emailed to point out a mistake in my latest blog post about the Eurovision Song Contest 2015. According to the email, I wrongly described an audio clip as containing the words any time, any place, I’m yours, when the second word should really be town:
I’m always grateful when readers tell me about typos (typographical errors) in my posts. One reader has emailed to point out a mistake in my latest blog post about the Eurovision Song Contest 2015. According to the email, I wrongly described an audio clip as containing the words any time, any place, I’m yours, when the second word should really be town:
Actually, it wasn’t an error. It’s easy enough to show that the intended word in Austria’s song ‘I Am Yours’ really is time. The official lyrics on the eurovision.tv website are here, and you can see them synchronized with the song on YouTube here. But that doesn’t address the interesting phonetic issue: does the word really sound like town and, if so, how can it really be time?
First, yes, it certainly does sound rather like town if you take it out of context:
And context is undeniably relevant. ‘Any time, any place’ is a common English phrase (indeed, it was the name of a hit song by Janet Jackson), whereas ‘any town, any place’ would be rather odd. Even so, it’s conceivable that Dodo (Dominic) Muhrer, lead singer of Austrian band the Makemakes, mademade a pronunciation error; after all, he’s presumably not a native speaker of English. However, when I was watching the show, my native-English ears had no difficulty in hearing the intended word, time.
In fact, Mr Muhrer was doing a very good job of singing in the widely-used pop-rock accent of English, which has its roots in the speech of the American South and, relatedly, in African American English. (I explored the socio-phonetic background in two blog posts here and here).
The feature we’re concerned with is the vowel of words like time (and I, eye, my, high, etc). In the standard spoken accents of Britain and America, this vowel is a ‘diphthong’, gliding from a quality like a to a quality like i. But in pop-rock English, we typically get a smoother vowel like aa. Here’s the Englishman Mick Jagger singing ‘time is on my side’ as taam is on maa saad:
So, in pop-rock English, the vowel of time doesn’t have to glide towards i. But in the singing of Dodo Muhrer there’s a different kind of glide at the end of the vowel, which led my email correspondent to hear the vowel of town. The explanation, I think, is that Mr Muhrer is letting his vocal organs slide, rather early, away from aa and towards their positions for the following m at the end of the word time. This involves the tongue raising to a more neutral position and the lips moving closer together – quite similar to the adjustments which occur towards the end of the ow vowel of town.
Is this ‘early sliding’ an Austrian error? No. Here’s the American superstar Cher doing very much the same thing in her hit ‘If I Could Turn Back Time’:
If we extract Cher’s time from its context, it might possibly be town:
The poor Makemakes may have come joint last in the Eurovision Song Contest, earning what the British media like to refer to as nul points, but Mr Muhrer can take comfort in knowing that he’s mastered the English pop-rock accent pretty well.
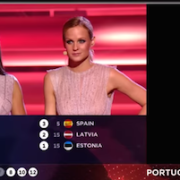
Where are you?
 The voting stage of the Eurovision Song Contest 2015 provided several of those wonderful moments when TV contact with one of the countries is lost and its announcer disappears from the screen. When Portugal went black, one of the show’s Austrian hosts said, ‘Where are you?’:
The voting stage of the Eurovision Song Contest 2015 provided several of those wonderful moments when TV contact with one of the countries is lost and its announcer disappears from the screen. When Portugal went black, one of the show’s Austrian hosts said, ‘Where are you?’:
The speaker, Alice Tumler, has a basically Southern-British type of accent; according to her Wikipedia page, she studied for some time in London. But her pronunciation in that clip isn’t what you’d hear from native Southern Brits. Ms Tumler glides directly from where to are without pronouncing a linking r.
Words like where used to be pronounced in England and Wales with a final r which was lost around the end of the 18th century (the r survives in Scotland, Ireland and North America). But the r typically re-appears when a vowel follows in the next word. And to be fair, Ms Tumler occasionally did use a linking r during the show, for example in ‘there‿it is’:
Note that the effect of linking r is to prevent vowels from coming into contact. Languages often try to prevent vowels from touching, and Southern British English is particularly allergic to this. Keeping vowels apart makes speech clearer. When I misunderstand non-native speech, it’s often because the speaker has allowed two vowels to blur into one another. Here’s Ms Tumler again:
In that clip she’s saying ‘when their names were announced’, blurring were into announced without a linking r to keep the vowels apart.
Wherever I teach around the world, I ask people to look at dictionary entries like the following for the word far, and to tell me the meaning of the superscript or bracketed ‘r’ in the UK/British transcriptions: The most common answers that I get are: 1. pronounce the r in American English (which isn’t really an answer); 2. the r is simply optional – speakers can either choose to pronounce it or not; 3. the r should be pronounced ‘slightly’. No. The right answer is that it indicates linking r, which is pronounced, as I said above, when a vowel follows in the next word.
The most common answers that I get are: 1. pronounce the r in American English (which isn’t really an answer); 2. the r is simply optional – speakers can either choose to pronounce it or not; 3. the r should be pronounced ‘slightly’. No. The right answer is that it indicates linking r, which is pronounced, as I said above, when a vowel follows in the next word.
Further notes
There’s a lot more on linking r in my long blog post here. A related phenomenon is ‘hard (or glottal) attack’, which I touched on in the blog post here.

Yeah…she yells at me a lot
 A Japanese colleague has asked me to clarify the meaning of a short phrase of (American) English. It comes from Disney’s English-language soundtrack to Hayao Miyazaki’s animated masterpiece Tonari no Totoro となりのトトロ ‘My Neighbor Totoro’.
A Japanese colleague has asked me to clarify the meaning of a short phrase of (American) English. It comes from Disney’s English-language soundtrack to Hayao Miyazaki’s animated masterpiece Tonari no Totoro となりのトトロ ‘My Neighbor Totoro’.
The context is this. Two sisters visit their mother in hospital. Finding that the older sister has been cutting the hair of the younger sister Mei, the mother says to Mei, ‘What a lucky girl you are.’ My colleague thought that young Mei’s reply sounded like ‘Yeah…she yells at me a lot.’
If Mei’s reply were ‘Yeah…she yells at me a lot’, it would be strange, or unusually ironic for a small child. ‘Yeah’ expresses agreement that she’s a lucky girl; by contrast, ‘she yells at me a lot’ is inconsistent with being lucky. To yell at someone carries an implication of anger, especially in American English. (British English tends to favour shout at in the same kind of context.)
So what’s going on?
Native English speakers with reasonably good loudspeakers and ears may well have worked out the solution: between ‘Yeah’ and ‘she yells at me a lot’ is the word but. This can be made more apparent by acoustically ‘compressing’ the recording, which makes the quiet parts closer in amplitude to the louder parts, and by time-stretching it. Here is Yeah but she, first in the original, then compressed, then compressed and stretched:
There we can perceive more clearly the pop as the speaker’s lips separate for the b of but. There’s no following vowel to speak of, but then the speaker’s tongue forms the t which is released directly into the sh of she, creating something more like b’che (in phonetic transcription, btʃi or ptʃi).
Non-native readers shouldn’t conclude that this is a mispronunciation, or an oddity of child speech (actor Elle Fanning was about seven at the time of the recording), or an obscure dialect feature. But is one of a number of super-frequent little words which often appear in very weak forms – in fact, ‘weak forms’ is what they’re generally called. These weak forms – and, as, at, but, from, of, was, etc – may have the short, colourless vowel schwa, ə, or, as in this example, no vowel at all.
Weak forms are typically ‘proclitic’, which means they lean for support onto the following word. They help to give English its weak-strong ‘iambic’ rhythm. A consequence is that English phrases very often have weak beginnings, eg ‘but she yells at me a lot’. Non-natives, on the other hand, tend not to use weak forms so much when they speak English, and not to hear them when they listen to English. This is particularly my experience with Japanese students and clients. As we see in this example, however, they can be quite important for meaning.
Further notes
For simplicity I omitted above to say that my Japanese colleague actually perceived the past tense form yelled in the clip. I’m pretty sure that it’s the habitual present tense yells, although its final consonant is weak and not very sibilant. I’d attribute this to the speaker’s young age. Sibilant sounds have complex articulations and often take quite a long time to be fine-tuned in children’s speech. Elle Fanning has clear, standard sibilants today.
Lastly, the word lot in the clip provides an excellent example of a final stop consonant ‘without audible release’. This means that the final t is formed but not then exploded. Such unreleased final stops are absolutely routine in American English, and British actors need to copy them if they want to do American accents.
